toFHIR Features: Schema Inferring

Okan Mercan
Software EngineerDefining schemas in toFHIR is simple for most datasets. However, when working with complex schema, the process can become more time-consuming. You may need to go through each column, carefully defining its structure and repeatedly testing your mappings to ensure they work as expected with real data. This define–test–adjust cycle can extend the setup time in those more demanding scenarios.
But what if there were a smarter way? Imagine simply providing your raw data — whether from a database or file system — and having toFHIR automatically analyze it and generate the corresponding schema for you. No manual column definitions. No guesswork. Just intelligent automation.
This is where toFHIR’s schema inference feature comes into play. With just a sample of your source data, toFHIR can infer the structure, detect field types, and create a ready-to-use schema adjusted to your dataset. It’s a powerful capability that saves time, reduces human error, and lets you focus on what matters most: building efficient, interoperable data pipelines.
In the next section, we’ll walk through how this feature works in practice — and how it can speed up your workflow dramatically.
See Schema Inference in Action
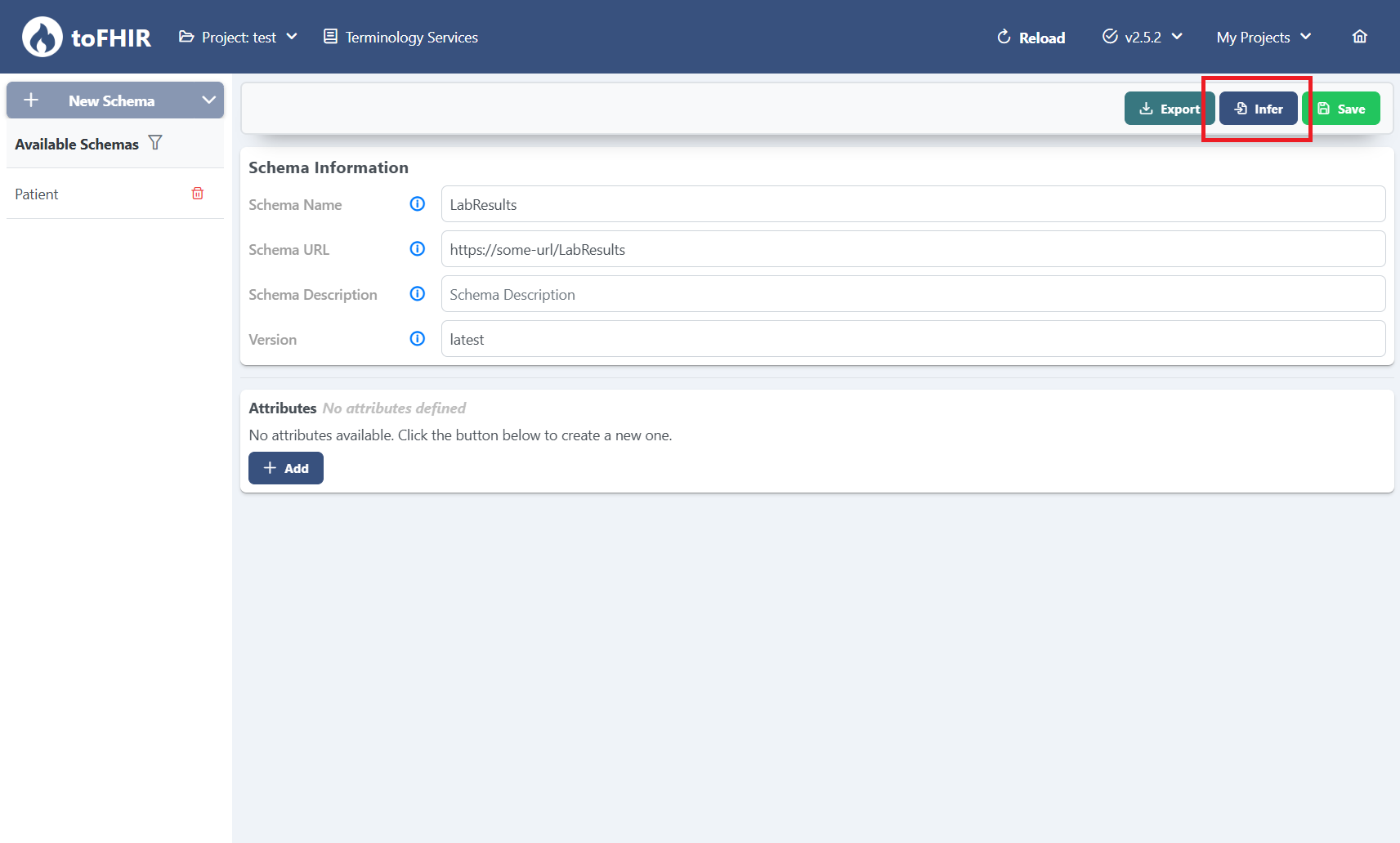
Let’s say you have a CSV file containing lab results — with 12 different columns representing several data rows. You want to use this file in toFHIR and map its contents into FHIR resources. Normally, your first step would be to manually define each of these columns on the schema page of the toFHIR web interface — a necessary but time-consuming task. But here’s the good news: on that very same page, you’ll notice a small button that can change everything. It allows you to launch an inference task, letting toFHIR automatically analyze your data and generate the schema for you. No more manual column definitions. Just smart, instant schema generation that gets you started faster.
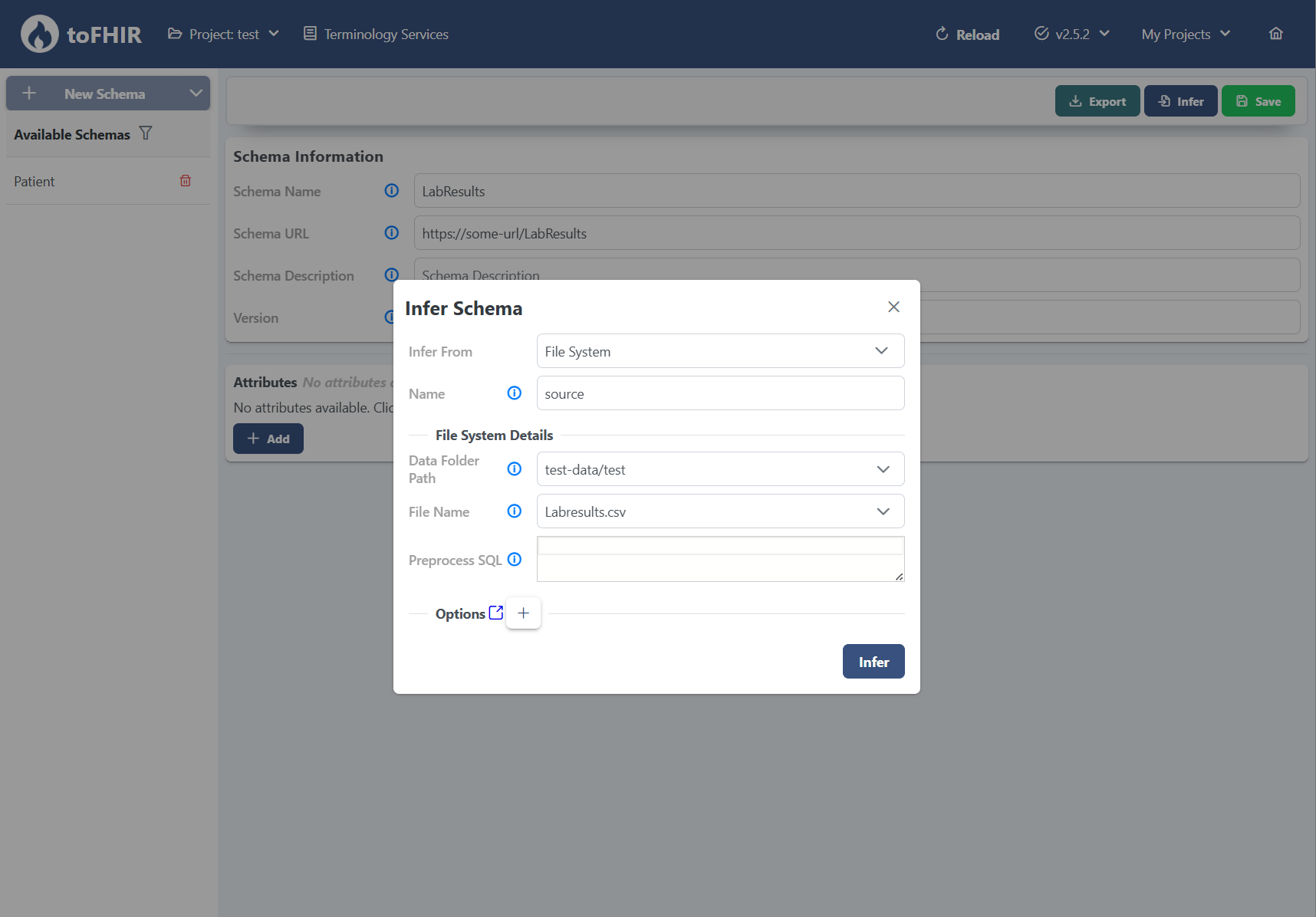
When we click the infer button, a pop-up window appears. This is where toFHIR asks us to define how it can reach the source data — whether it's from a database or a file system. In this step, we provide the connection details: where the data is stored and how toFHIR can reach it.
One extremely powerful option here is the ability to define a preprocess SQL statement. This allows you to run SQL queries on the source data before schema inference begins — enabling you to filter, join, or transform the data as needed, right from the start.
In our example, we simply define the folder path and the file name of the CSV we want to use. Once everything is set, we click the infer button, and toFHIR begins analyzing the data to automatically generate the schema.
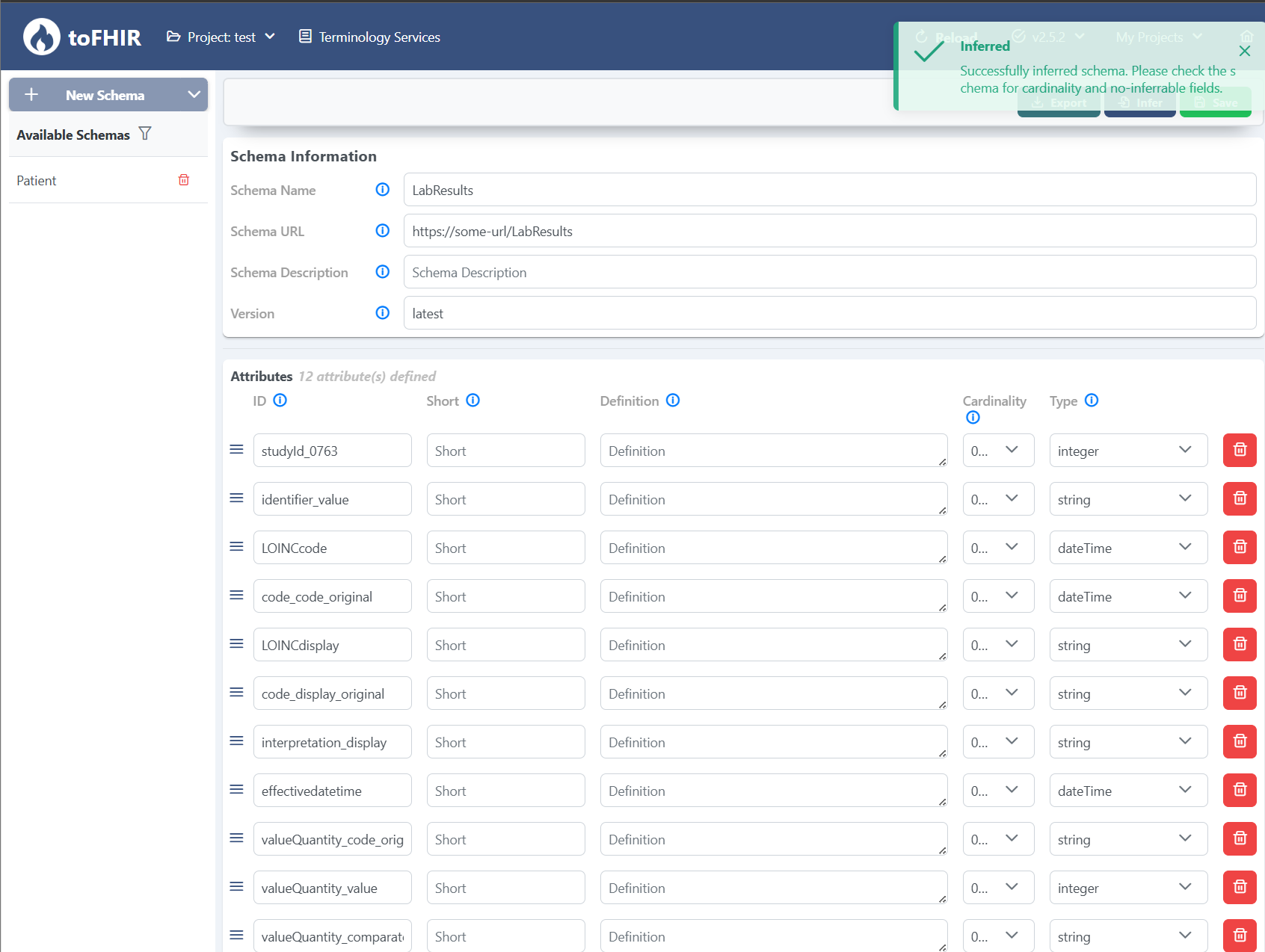
The inferred schema is displayed below. The column names, cardinalities, and data types have been automatically extracted from the source file. If needed, you can make further edits — or simply save the schema and move on to defining your mappings!
Schema inference is just one of the many features that makes toFHIR a powerful and user-friendly tool for transforming your data into FHIR resources. By automating the schema creation process, you can save time, reduce manual effort, and get started with your data mappings much faster. Whether you're working with files or databases, toFHIR is designed to simplify your workflow and help you focus on what matters most.
Curious to see how it works with your own data? Give schema inference a try today — and if you have any questions or need support, don’t hesitate to reach out. We’d love to hear from you and help you get started!
No worries — we’ve covered the basics in our Getting Started Tutorial. If you’re new to terms like schema, mapping, or job, we recommend checking it out first for a smoother experience.